Massif¶
Massif 是 Valgrind 工具套件中的一个内存分析工具。它的目的是提供程序生命周期内动态内存使用的详细视图。具体来说,它记录堆和栈的内存使用情况。
堆是使用诸如 malloc 之类的函数分配的内存区域。它会按需增长,通常是程序中最大的内存区域。栈是存储函数所有局部数据的区域。这包括 C 语言中的“自动”变量和子例程的返回地址。栈通常比堆小得多,也更活跃。我们不会显式地考虑栈,因为 Massif 将其视为堆的另一个部分。Massif 还提供有关用于管理堆的内存使用情况的信息。
Massif 会生成两个输出文件:一个后脚本文件中的图形概述,以及一个文本文件中的详细分解。
在 GNOME 中使用 Massif¶
Massif 选项很少,对于许多程序来说,不需要它们。但是对于 GNOME 应用程序,其中内存分配可能深埋在 glib 或 GTK 中,需要增加 Massif 深入调用栈的层数。这可以使用 --depth 参数 来实现。默认值为 3;将其增加到 5 将保证调用栈能够深入到您的代码中。为了提供代码上下文,可能还需要增加一两层。由于细节级别会迅速变得难以承受,因此最好从较小的深度参数开始,仅在明显不足时才增加它。
同样,告诉 Massif GLib 中哪些函数分配内存也很有用。它会从报告中删除不必要的函数调用层,让您更清楚地了解哪些代码正在分配内存。GLib 中的分配函数是 g_malloc、g_malloc0、g_realloc、g_try_malloc 和 g_mem_chunk_alloc。您可以使用 --alloc-fn 选项告诉 Massif 这些函数。
因此,您的命令行应该如下所示
valgrind --tool=massif \
--depth=5 \
--alloc-fn=g_malloc \
--alloc-fn=g_realloc \
--alloc-fn=g_try_malloc \
--alloc-fn=g_malloc0 \
--alloc-fn=g_mem_chunk_alloc \
swell-foop
Swell Foop 是我们将用作示例的程序。请注意,由于 valgrind 模拟 CPU,因此运行速度会非常慢。您还需要大量的内存。
Massif 引导优化示例¶
解释结果¶
Massif 的图形输出在很大程度上是自解释的。每个条带代表一个函数随时间分配的内存。一旦确定哪些条带使用的内存最多,通常是顶部的大粗条带,您就需要查阅文本文件以获取详细信息。
文本文件以分层结构排列,顶部是按递减时空排序的最坏内存使用者列表。在下方是进一步的部分,每个部分在您向下调用栈进行时,将结果分解为更精细的细节。为了说明这一点,我们将使用上述命令的输出。
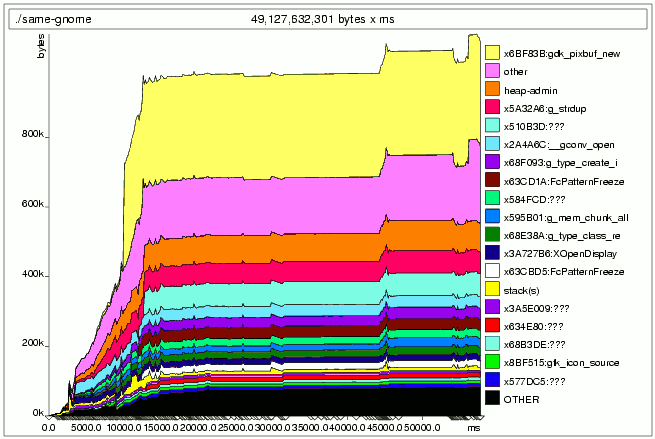
Swell Foop 程序未优化的 Massif 输出。¶
上面的图像显示了 Massif 的典型后脚本输出。这是您玩一次 Swell Foop (版本 2.8.0) 然后退出后获得的结果。后脚本文件将具有类似 massif.12345.ps 的名称,文本文件将命名为 massif.12345.txt。中间的数字是所检查程序的进程 ID。如果您实际尝试此示例,您会发现每个文件有两个版本,数字略有不同,这是因为 Swell Foop 启动了第二个进程,Massif 也跟踪该进程。我们将忽略第二个进程,因为它消耗的内存很少。
在图表的顶部,我们看到一个大型黄色条带,标记为 gdk_pixbuf_new。这似乎是一个理想的优化候选对象,但我们需要使用文本文件来找出哪些代码正在调用 gdk_pixbuf_new。文本文件的顶部将如下所示
Command: ./swell-foop
== 0 ===========================
Heap allocation functions accounted for 90.4% of measured spacetime
Called from:
28.8% : 0x6BF83A: gdk_pixbuf_new (in /usr/lib/libgdk_pixbuf-2.0.so.0.400.9)
6.1% : 0x5A32A5: g_strdup (in /usr/lib/libglib-2.0.so.0.400.6)
5.9% : 0x510B3C: (within /usr/lib/libfreetype.so.6.3.7)
3.5% : 0x2A4A6B: __gconv_open (in /lib/tls/libc-2.3.3.so)
带有“=”号的行指示我们在堆栈跟踪中下降了多少层,在本例中,我们位于顶部。之后,它列出了按递减时空排序的内存使用量最大的用户。时空是使用的内存量和使用时间长度的乘积。它对应于图中条带的面积。此文件部分告诉我们我们已经知道的内容:大部分时空都用于 gdk_pixbuf_new。要找出调用 gdk_pixbuf_new 的内容,我们需要在文本文件中进一步搜索
== 4 ===========================
Context accounted for 28.8% of measured spacetime
0x6BF83A: gdk_pixbuf_new (in /usr/lib/libgdk_pixbuf-2.0.so.0.400.9)
0x3A998998: (within /usr/lib/gtk-2.0/2.4.0/loaders/libpixbufloader-png.so)
0x6C2760: (within /usr/lib/libgdk_pixbuf-2.0.so.0.400.9)
0x6C285E: gdk_pixbuf_new_from_file (in /usr/lib/libgdk_pixbuf-2.0.so.0.400.9)
Called from:
27.8% : 0x804C1A3: load_scenario (swell-foop.c:463)
0.9% : 0x3E8095E: (within /usr/lib/libgnomeui-2.so.0.792.0)
and 1 other insignificant place
第一行告诉我们,我们现在已经深入到堆栈的四层。下面是导致从这里到 gdk_pixbuf_new 的函数调用的列表。最后,有一个列表,其中包含位于下一层并调用这些函数的函数。当然,还有第 1、2 和 3 层条目,但这是第一个到达 GDK 代码并通过 Swell Foop 代码的层级。从这个列表中,我们可以立即看到问题代码是 load_scenario。
现在我们知道我们代码的哪一部分正在使用所有时空,我们可以查看它并找出原因。事实证明,load_scenario 从文件加载一个 pixbuf,然后从未释放该内存。确定了问题代码后,我们可以开始修复它。
根据结果采取行动¶
减少时空消耗是好的,但有两种减少时空消耗的方法,它们并不相等。您可以减少分配的内存量,也可以减少内存的分配时间。考虑一个只有两个进程运行的模拟系统。两个进程都用尽了所有的物理 RAM,如果它们有任何重叠,系统就会交换,一切都会变慢。显然,如果我们将其每个进程的内存使用量减少一半,它们就可以和平共处,而无需交换。如果我们改为将内存分配时间减少一半,那么这两个程序可以共存,但前提是它们的高内存使用期不会重叠。因此,减少分配的内存量更好。
不幸的是,优化的选择也受到程序需求的限制。Swell Foop 中 pixbuf 数据的大小由游戏图形的大小决定,无法轻易减少。但是,将其加载到内存中的时间可以大大减少。下图显示了在修改为处理 pixbuf 后 Massif 对 Swell Foop 的分析,这些 pixbuf 一旦加载到 X 服务器中就会被释放。
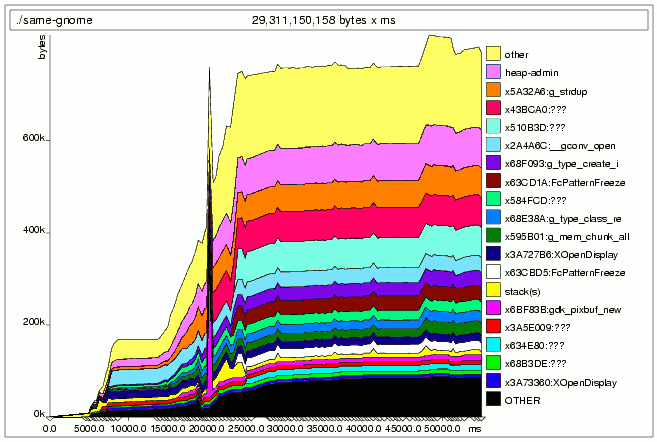
优化 Swell Foop 程序的 Massif 输出。¶
gdk_pixbuf_new 的时空使用现在是一个细条,它只会在短时间内激增(现在是第十六条条带,并以品红色阴影显示)。作为奖励,峰值内存使用量下降了 200 kB,因为激增发生在其他内存分配之前。如果同时运行这两个进程,峰值内存使用重叠的几率,以及交换的风险,将会很低。
我们能做得更好吗?对 Massif 的文本输出进行快速检查显示:g_strdup 是新的主要罪魁祸首。
Command: ./swell-foop
== 0 ===========================
Heap allocation functions accounted for 87.6% of measured spacetime
Called from:
7.7% : 0x5A32A5: g_strdup (in /usr/lib/libglib-2.0.so.0.400.6)
7.6% : 0x43BC9F: (within /usr/lib/libgdk-x11-2.0.so.0.400.9)
6.9% : 0x510B3C: (within /usr/lib/libfreetype.so.6.3.7)
5.2% : 0x2A4A6B: __gconv_open (in /lib/tls/libc-2.3.3.so)
但是,如果我们仔细观察,我们会发现它被调用了许多次,很多次。
== 1 ===========================
Context accounted for 7.7% of measured spacetime
0x5A32A5: g_strdup (in /usr/lib/libglib-2.0.so.0.400.6)
Called from:
1.8% : 0x8BF606: gtk_icon_source_copy (in /usr/lib/libgtk-x11-2.0.so.0.400.9)
1.1% : 0x67AF6B: g_param_spec_internal (in /usr/lib/libgobject-2.0.so.0.400.6)
0.9% : 0x91FCFC: (within /usr/lib/libgtk-x11-2.0.so.0.400.9)
0.8% : 0x57EEBF: g_quark_from_string (in /usr/lib/libglib-2.0.so.0.400.6)
and 155 other insignificant places
现在我们面临优化工作的边际收益递减。该图表提示了另一种可能的方案: “other” 和 “heap admin” 条带都很大。这告诉我们,正在从各种地方进行许多小的分配。消除这些分配将是困难的,但如果可以将它们分组,则可以使单个分配更大,并减少“堆管理”开销。
注意事项¶
有几件事需要注意:首先,时空仅报告为百分比,您必须将其与程序的总体大小进行比较,以确定内存量是否值得追求。该图表,其垂直轴为千字节,对此很有用。
其次,Massif 仅考虑程序自己的内存使用情况。如果您的应用程序使用 IPC 并引用不同进程中的对象,Massif 将不会考虑它们的内存占用。在 Swell Foop 示例中,我们实际上只是将内存消耗从客户端 pixbuf 移动到服务器端 pixmap。即使我们作弊了,也有性能提升:将图像数据保存在 X 服务器中可以加快图形例程的速度,并消除大量的进程间通信。